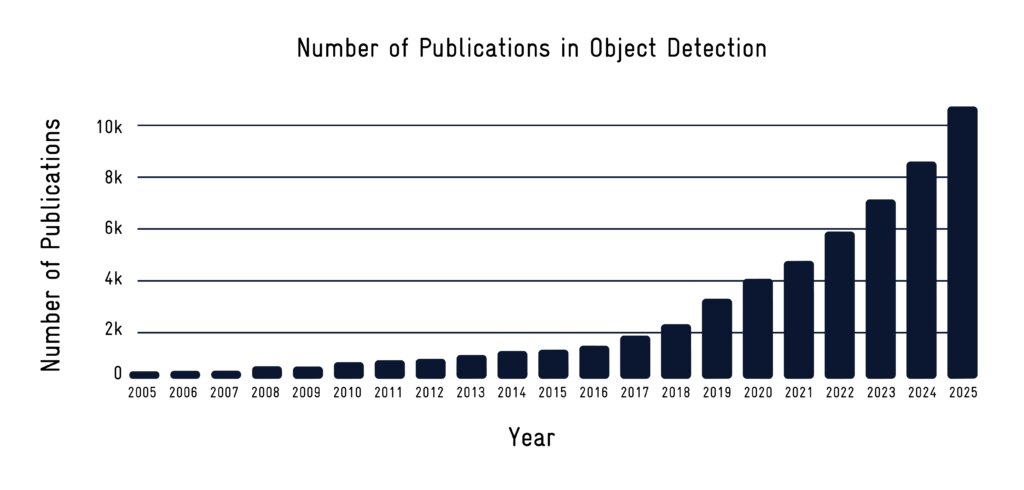

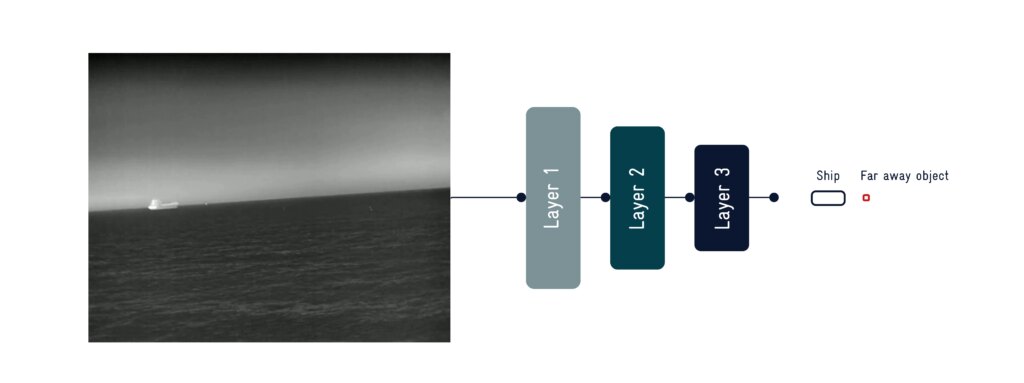


AI object detection identifies and locates maritime objects using deep neural networks, enabling safer vessel navigation and collision avoidance.

For more than 40 years, Privilège Marine has built catamarans designed for serious bluewater cruising, where safety, robustness, and comfort are non-negotiable. Today, that commitment takes a new step forward.

We received the jury’s Special Mention at the EUROMARITIME Awards 2026. Moreover, this distinction was created by the jury to recognize technology that has demonstrated transformative impact on maritime detection and surveillance.