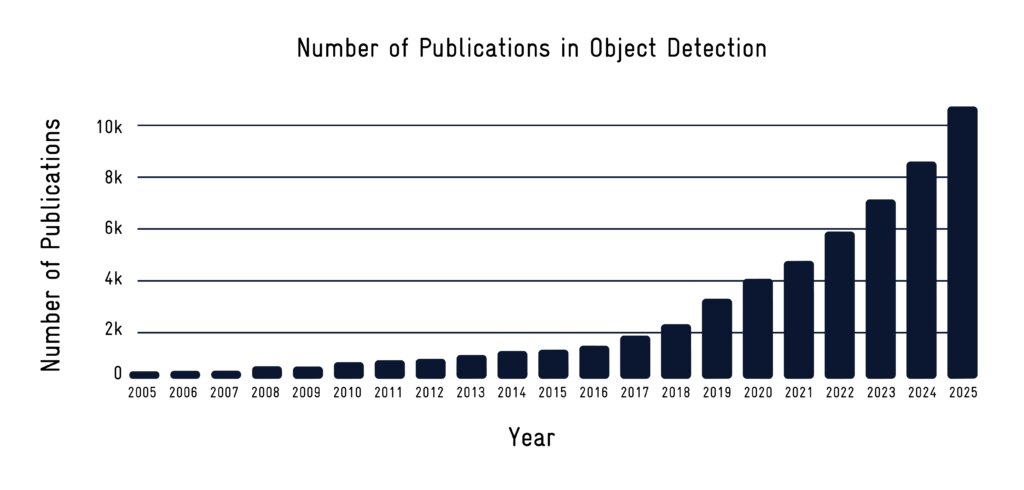

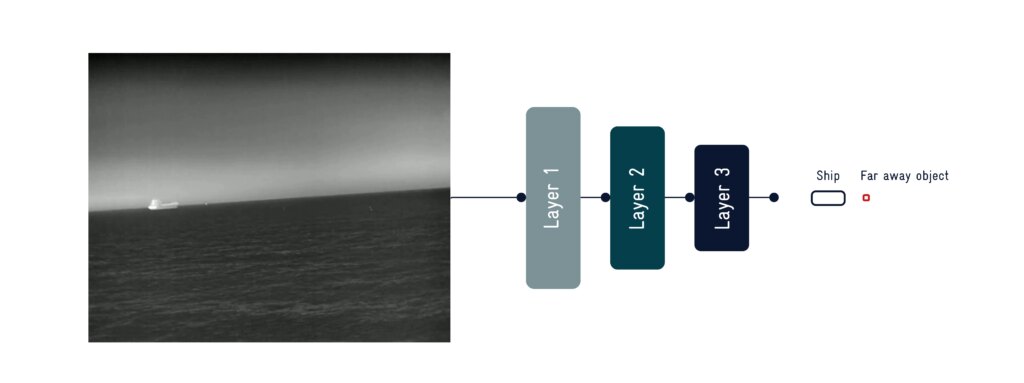


Il rilevamento di oggetti con IA identifica e localizza gli oggetti marini utilizzando reti neurali profonde, consentendo una navigazione più sicura e la prevenzione delle collisioni.

Da oltre 40 anni, Privilège Marine costruisce catamarani progettati per le crociere d’altura, dove sicurezza, robustezza e comfort sono elementi imprescindibili. Oggi questo impegno compie un nuovo passo avanti.

Abbiamo ricevuto la menzione speciale della giuria agli EUROMARITIME Awards 2026. Inoltre, questa distinzione è stata creata dalla giuria per riconoscere la tecnologia che ha dimostrato un impatto trasformativo sul rilevamento e la sorveglianza marittima.