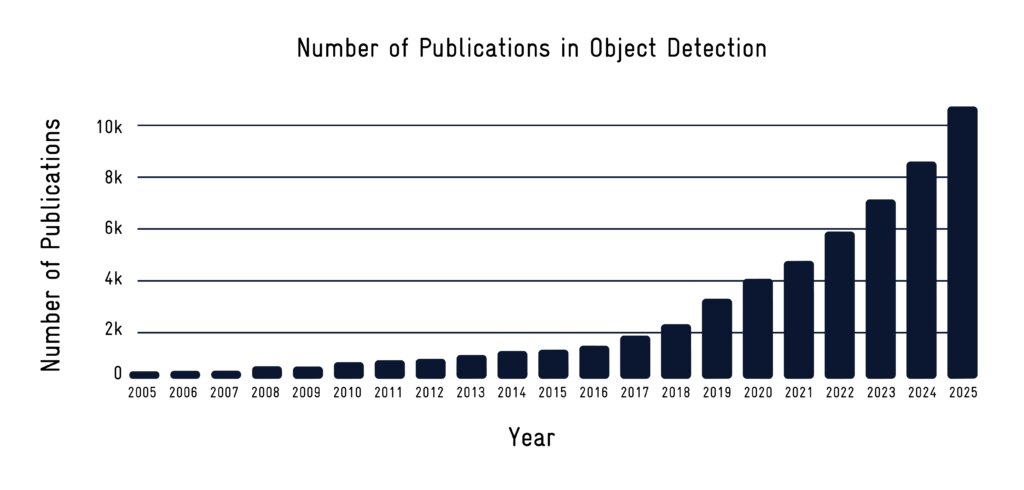

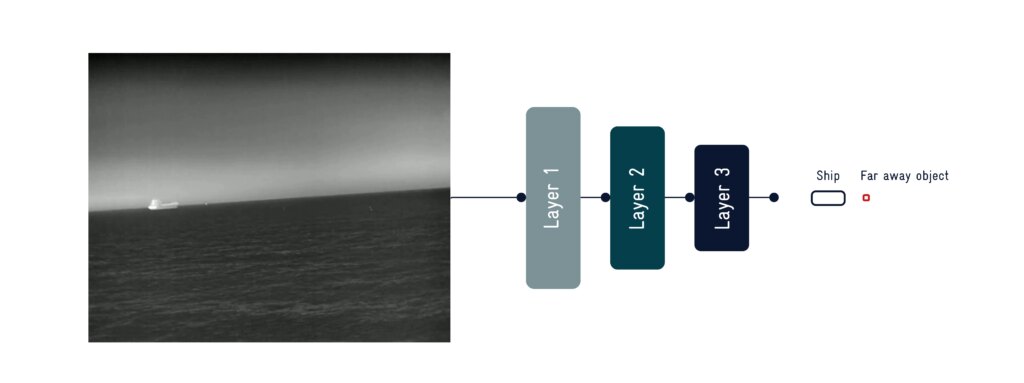


SEA.AI se développe en Amérique du Nord, avec une nouvelle équipe, un meilleur support et une plus grande disponibilité. Nous renforçons notre présence en Amérique du Nord avec de nouveaux talents, un soutien accru et un accès plus large à nos systèmes de sécurité.
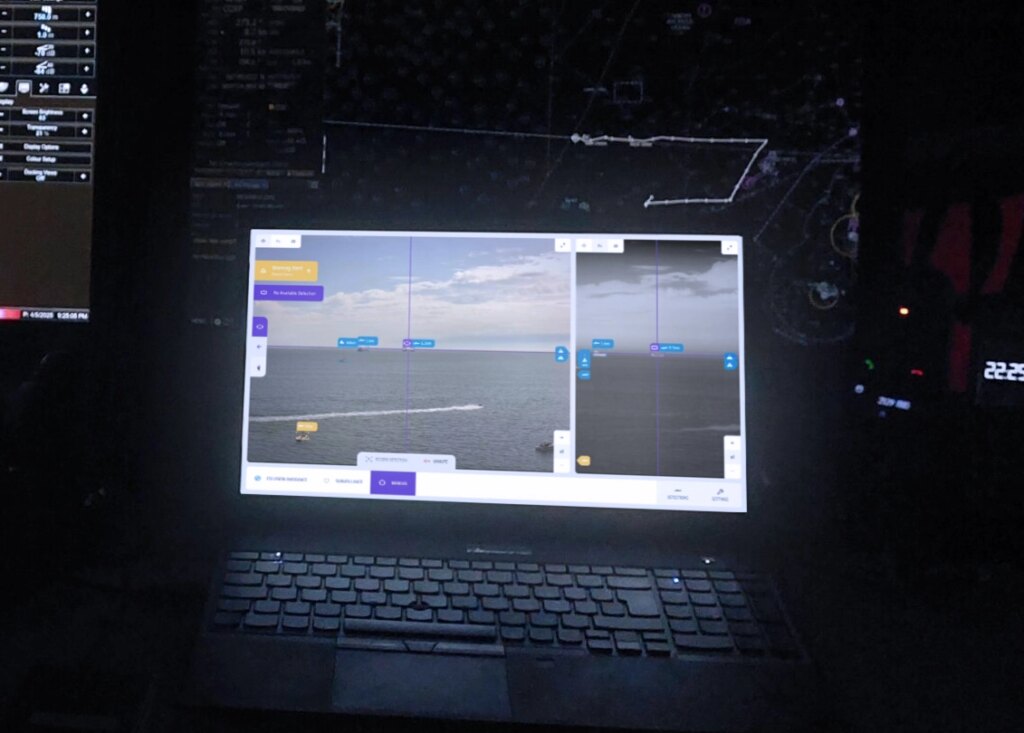
La détection vous dit ce qui est en mer. Le suivi multi-objets vous dit ce qu’est chaque objet, d’où il vient et où il va, pour chaque objet de la scène simultanément. C’est la différence entre un instantané et un renseignement opérationnel.

La surveillance maritime dépend de l’AIS et du radar. Quand l’un ou l’autre est défaillant, masqué ou brouillé, l’image opérationnelle disparaît. L’intelligence visuelle par IA est la réponse à cet écart.