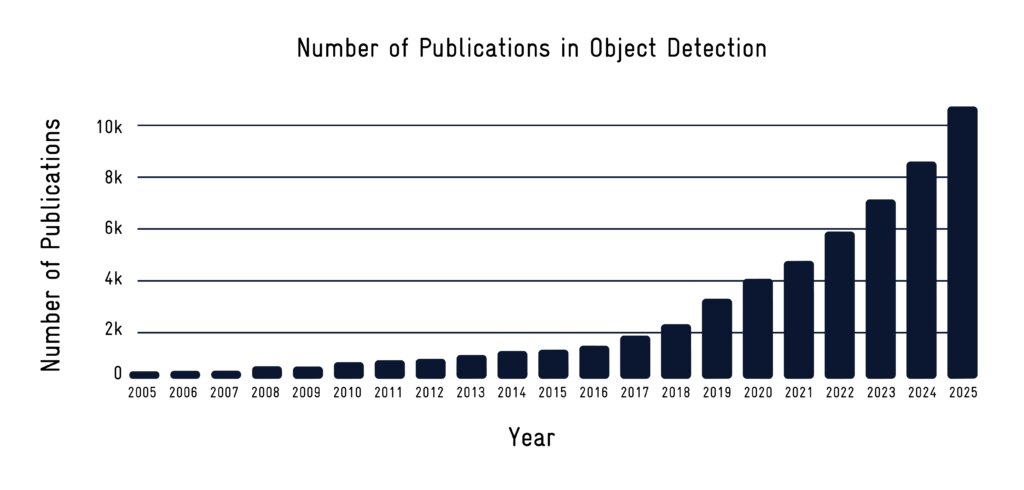



SEA.AI crece en Norteamérica: nuevo equipo, mejor asistencia y mayor disponibilidad. Estamos reforzando nuestra presencia en Norteamérica con nuevos talentos, un mayor apoyo y un acceso más amplio a nuestros sistemas de seguridad.
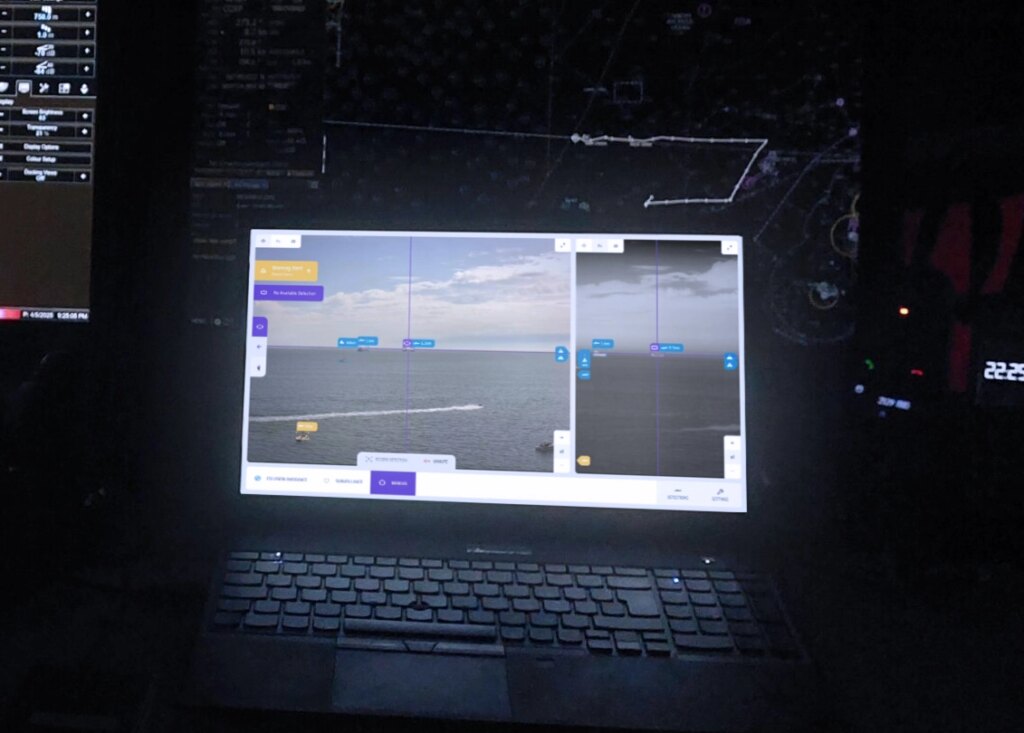
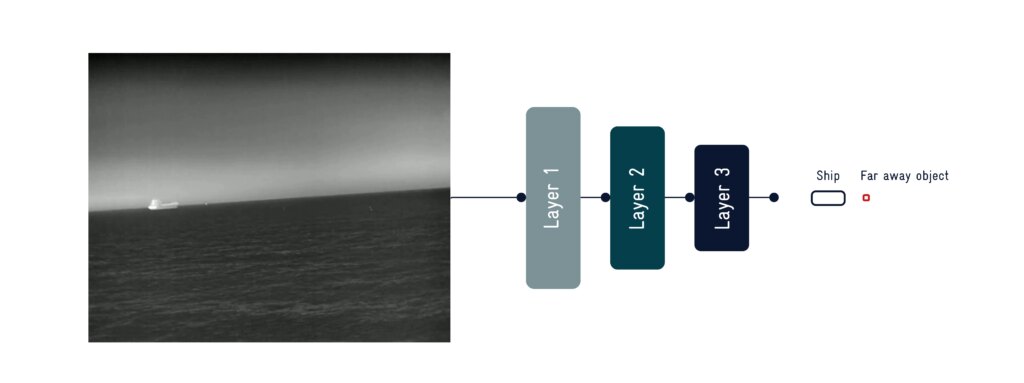
La detección te dice qué hay en el mar. El seguimiento multi-objeto te dice qué es cada contacto, de dónde viene y adónde va, para cada objeto de la escena de forma simultánea. Esa es la diferencia entre una instantánea y la inteligencia operativa.

La vigilancia marítima depende del AIS y el radar. Cuando uno de los dos falla, se oscurece o se interfiere, el cuadro operativo desaparece. La inteligencia visual con IA es la respuesta a esta brecha.